Prevalent Wisdom
Perusing some threads while designing the schema for $CURRENT_JOB, I came across a common refrain that one should never use UUIDs as primary keys.
-
At my job, we use UUID as PKs. What I can tell you from experience is DO NOT USE THEM as PKs (SQL Server by the way).
It’s one of those things that when you have less than 1000 records it;s ok, but when you have millions, it’s the worst thing you can do. Why? Because UUID are not sequential, so everytime a new record is inserted MSSQL needs to go look at the correct page to insert the record in, and then insert the record.
-
One post from Percona’s incredible blog offers up a few solutions with modifications to the UUID
-
Rick James has a post that offers up a solution using v1 UUIDs
In this post, I’m going to run the numbers myself and see if things have changed.
UUIDs? Why art thou so slow?
RFC4122 defines a UUID of being constructed as follows:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time_low |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time_mid | time_hi_and_version |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|clk_seq_hi_res | clk_seq_low | node (0-1) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| node (2-5) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
time_low: 4 Bytes (8 hex chars) from the integer value of the low 32 bits of UTC timestamptime_hi: 2 Bytes (4 hex chars) from the integer value of the high 16 bits of UTC timestamp
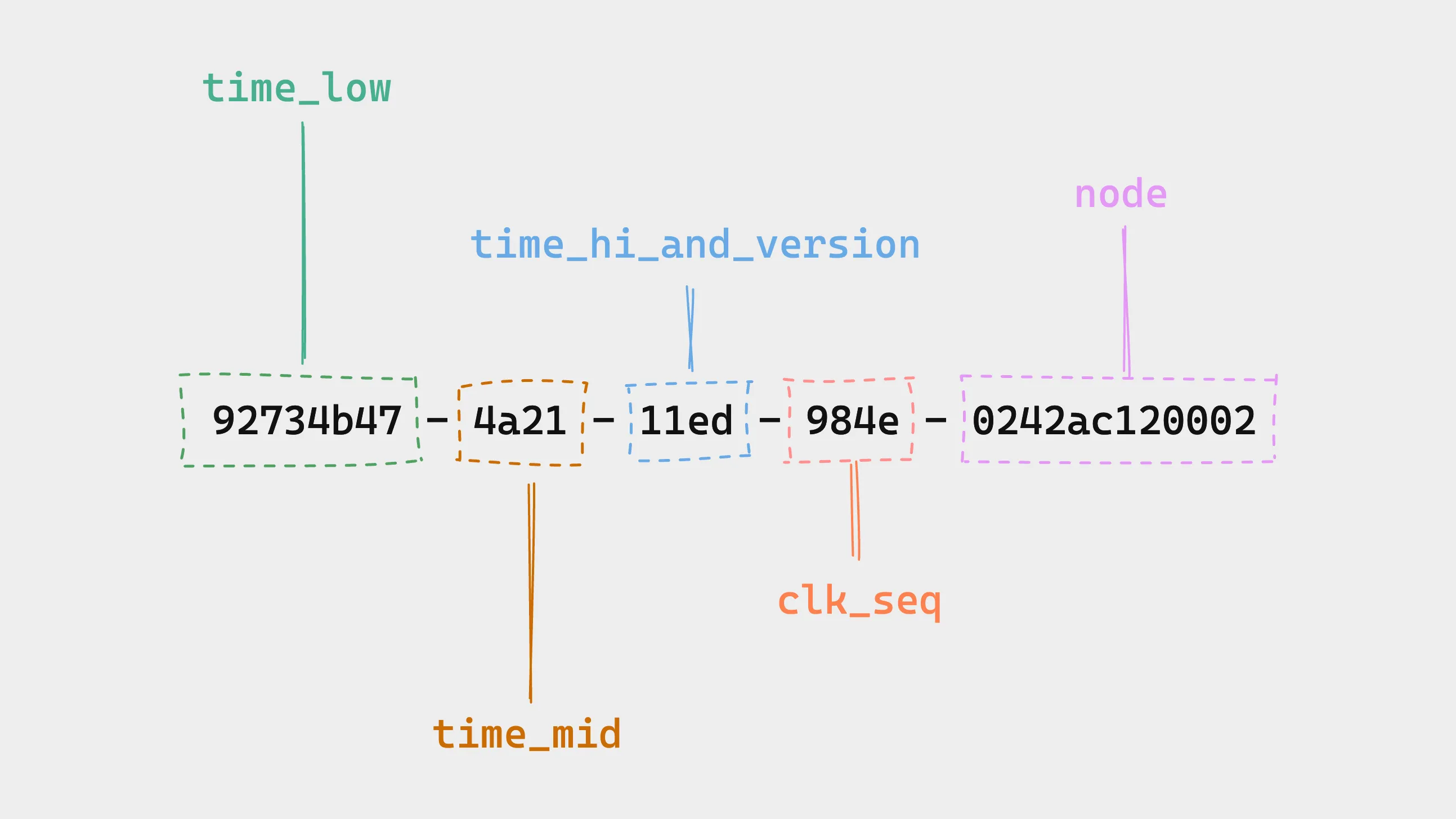
This makes a v1 UUID “somewhat” sequential. For example in MySQL:
-- Generate 5 UUIDs using the UUID() function
SELECT UUID();
+--------------------------------------+
| UUID() |
+--------------------------------------+
| 92734b47-4a21-11ed-984e-0242ac120002 |
| 934ae2ee-4a21-11ed-984e-0242ac120002 |
| 93b2a541-4a21-11ed-984e-0242ac120002 |
| 94470d9e-4a21-11ed-984e-0242ac120002 |
| 948c399b-4a21-11ed-984e-0242ac120002 |
+--------------------------------------+
Which all look pretty similar. The internal UUID() function generates a v1 UUID. MySQL now even has an extra flag on the UUID_TO_BIN() which:
If
swap_flagis 1, the format of the return value differs: The time-low and time-high parts (the first and third groups of hexadecimal digits, respectively) are swapped. This moves the more rapidly varying part to the right and can improve indexing efficiency if the result is stored in an indexed column.
But if I were to generate a v4 UUID, I’d get something like:
-- Select 5 UUIDs generated by an external library
SELECT uuid FROM test_table;
+--------------------------------------+
| uuid |
+--------------------------------------+
| 75c67472-d21e-4bb6-92c4-29f628dccfc5 |
| 367ef476-2130-4a23-a8a3-59d9b5ff2230 |
| 9f94ac0e-5ecb-4df3-acc0-d61169d10357 |
| 85812acb-3962-4dff-8fff-988bc57249d2 |
| 88c79d5c-43d3-4b55-ac15-de17b35deb33 |
+--------------------------------------+
Which are all over the place, making the database’s job of inserting them into the table much harder (if used as a primary key).
But why?
How MySQL (InnoDB) stores Primary Keys
For this discussion, I’ll only be considering InnoDB tables, the default storage engine in MySQL 8.0.30. Every time a new row is inserted:
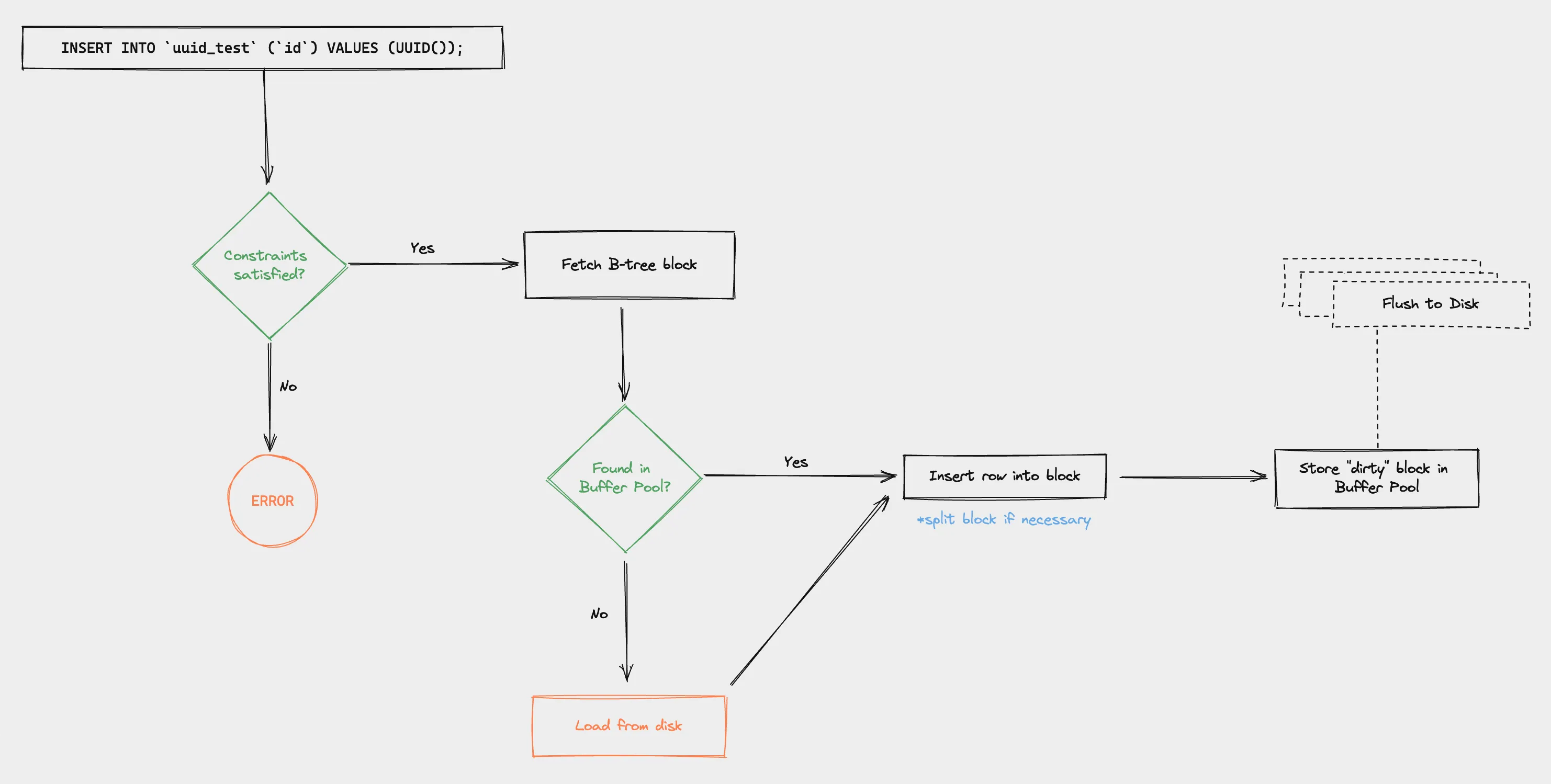
- Constraints are checked (unique, FK, etc.)
- B-tree block is fetched from the buffer pool, based on the PK, which dictates the order of the data in the block
- Row is inserted into the block, sometimes splitting the block if necessary
- Block is marked “dirty” in the buffer pool which is flushed to disk later (after a certain number of dirty blocks, or when the buffer pool is full)
This process works great for sequential PKs, ensuring that the new row is inserted at the end of the block. This permits batching the rows for the flush to disk, boosting performance.
However, if the PK is non-sequential, this could potentially be a massive slowdown. If the index is large enough to fit in the RAM, then all inserts are batched and delayed. If not, then every insert would trigger a read from disk. Furthermore, greater the randomness, greater the chance that a block would get flushed before the next insert can occur. Odds are, every insert would require 2 IOPs, one read one write. The chances of having a “hot” page are extremely slim. This is the core problem with a non monotonically increasing PK.
Benchmarks
Test Environment
- MySQL Server version: 8.0.30-0ubuntu0.22.04.1 (Ubuntu)
- Ubuntu 22.04.1 LTS x86_64
- CPU: AMD EPYC 7642 (4) @ 2.299GHz
Test Setup
All tables had just a single uuid column, which was also the primary key. Example:
CREATE TABLE `binary_16` (
`uuid` binary(16) NOT NULL,
PRIMARY KEY (`uuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
I tested the insert performance of the following IDs with both v1 and v4 UUIDs (sizes assume 10M rows, without accounting for the PK):
| ID Type | Size (MB) |
|---|---|
| INT(11) | 38.15 |
| BINARY(16) | 152.59 |
| VARCHAR(32) | 314.71 |
| CHAR(32) | 610.35 |
| CHAR(36) | 686.65 |
Note: It’s really hard getting MySQL to trigger a disk I/O, even while
inserting ~8,000 inserts/second over 2+ hours. In the end, I had to reduce the
RAM available to MySQL to 128M AND reduce the innodb_buffer_pool_size to
64M. It really is a testament to the efficiency of the InnoDB storage engine.
For the actual insert benchmarking, I used sysbench with the following command:
sysbench "$script" --threads=16 --warmup-time=30 --mysql-user=benchmark --mysql-password=password --mysql-db=benchmark --report-interval=1 --time=$1 run
The Lua scripts are available here.
Results
v1 UUIDs

Virtually the same performance between INT(11) AUTO_INCREMENT and CHAR(36) / CHAR(32) / VARCHAR(32) / BINARY(16) columns. So, always use v1 UUIDs, right? Well, not if you need the following:
- The ability to determine when the UUID was generated
- Inferring which machine generated the UUID
- Unguessable identifiers for your rows

What about UUIDv4?
v4 UUIDs
The p99 latencies show the real story here. The INT(11) AUTO_INCREMENT PK is ~6x faster than its CHAR(36) equivalent.

The difference starts to become apparent early on. But by the 500s mark (approximately 4M rows) there’s a gap of > 2,000 inserts/second!

What if I run the benchmark for twice the duration?

Now the gap widens to nearly 4,000 inserts/second! VARCHAR(32) inserts seemed to fail completely around the 4,300s mark (posibly ran out of storage).

The p99 difference seems to be even more pronounced (the scale of the Y-axis had to be changed). By this point, there were ~64 million rows in the table.
A Solution
Use an AUTO_INCREMENT primary key with an extra column for the UUID. Something like:
CREATE TABLE `binary_16` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`uuid` binary(16) NOT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
Now, generate a slugified version of the unique identifier on the application. For example, 75c67472-d21e-4bb6-92c4-29f628dccfc5 with id = 247389 becomes 75c67472-d21e-4bb6-92c4-29f628dccfc5.247389. During fetching, simply split the slugified ID on the . and use the latter part in your WHERE clause. On the returned row, match the requested vs. returned UUIDs. This solution was offered to me by my manager at my previous workplace and has been working out great for us!
What about PK exhaustion?
Use BIGINT. You will not run out.
UUIDs are big!
For storage of the UUIDs, I would recommend using a BINARY(16) data type making use of MySQL’s UUID_TO_BIN() and BIN_TO_UUID() functions.
According to another post on Percona’s Blog:
When the schema is based on UUID values, all these columns and indexes supporting them are char(36). I recently analyzed a UUID based schema and found that about 70 percent of storage was for these values.
A BINARY(16) column would reduce the storage size by 50% (from 36 bytes to 16 bytes). In practice, after accounting for the index it leads to a 77.7% reduction in storage size.
There’s another problem regarding the querying performance of a UUID. An INT can be compared 8 bytes at a time, while a UUID will need to be compared chare-by-char.
Conclusion
Turns out the the insert performance is really bad for v4 UUIDs. If a UUIDv1 fits your requirements, there’s no harm in using it as a primary key. In general, I would recommend against their usage.
This post was an exciting deep dive for me into the inner workings of InnoDB. I’m still just a novice so, please let me know on hi @ this domain if there’s something I missed.
Many thanks to the following folks for their assistance:
- Linode for the (free!) credits to run these benchmarks (Seriously, they’re awesome!)
- Isotopp from the
#mysqlchannel on IRC explaining the innards of InnoDB - Utkarsh from GameAway for helping me with those sweet charts